Animals are able to explore, seek food and remember how to reach it without much effort, yet similar performance with such faculty to plan and imagine shortest paths as well as adapt to changed environment are a long standing challenge in robotics. Robots are now able to reach goal and explore, but they usually require much hand-craft and engineering, as well as a specific adaptation to an environment, often taken aback by a change in the world. Still they are commonly used in industry, so actually, why would we even want to have a robot reasoning over navigation as an animal if we already have engineered solutions out there?
Why autonomous navigation?
Why do we want autonomous navigating agents?
Having an autonomous navigation in an agent means that we wouldn’t need human intervention, this results in reducing machine and humans errors, re-work, and, more importantly, risk rates. It is imagined to improve safety for humans in high-risk environments. For instance, underwater, space or in a contaminated area.
Why do we want a learning and adaptative agent?
An adaptative agent could navigate in a dynamic environment, when transposed to a new setting or just more efficiently, imagining shortcuts and considering new obstacles as well as considering risks etc. In essence it is to reduce human intervention in the robot settings and increase the capabilities of the robots.
How to navigate?
There are countless solutions being proposed going from SLAM and Active SLAM to machine learning and RL.
We believe another solution would be using active inference to navigate as well as spatial and temporal hierarchy?
Spatial hierarchy means adding abstraction, an example would be to have a high level representation of a country, a finer representation of where a city is in the country then where our building is in this city up to where our room is in this building etc.
Temporal hierarchy means planing on different time scale, as an example it would be how to reach the airport, we keep in mind this objective while planning how to reach the exit of our building as a middle step.
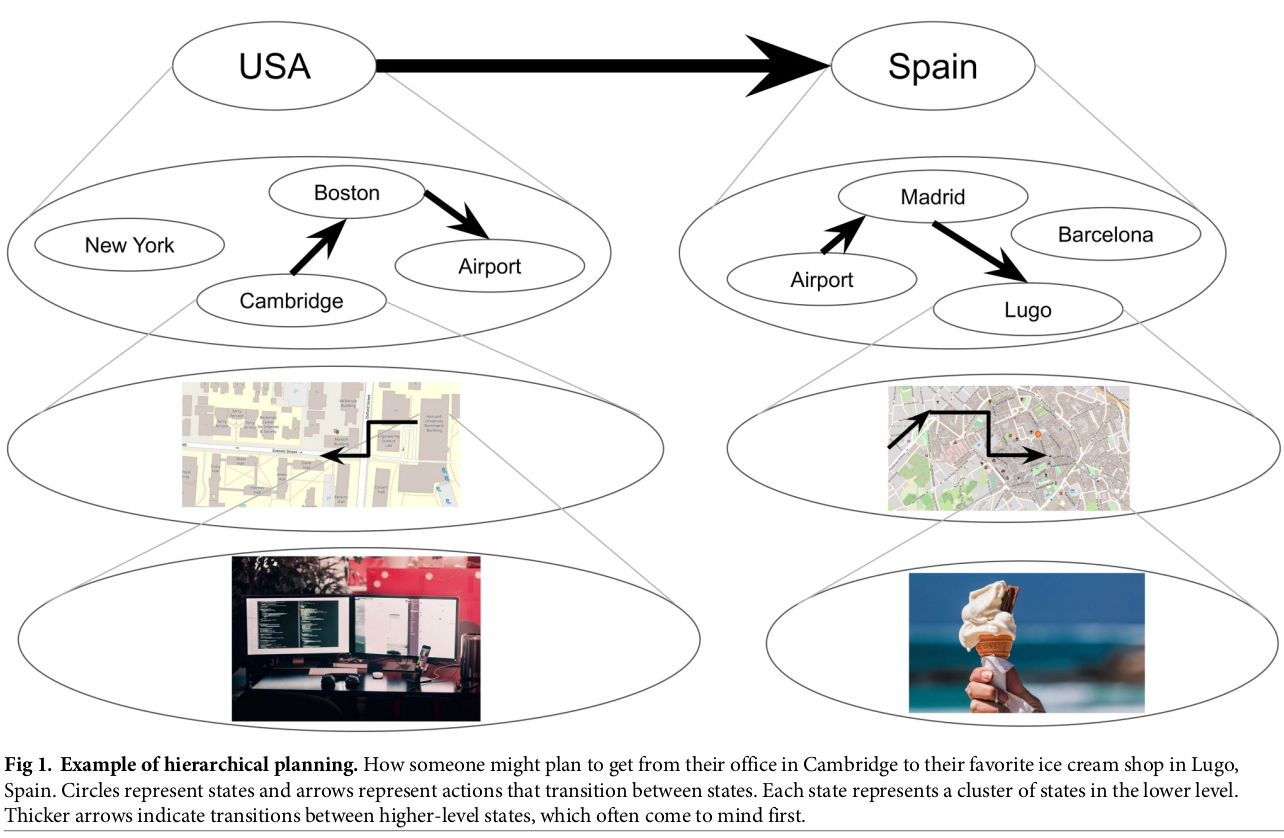 https://journals.plos.org/ploscompbiol/article/figure?id=10.1371/journal.pcbi.1007594.g001
https://journals.plos.org/ploscompbiol/article/figure?id=10.1371/journal.pcbi.1007594.g001
What are the advantages?
It means more flexibility, planning at different scales, defining objectives at different level of abstraction. while high level layers of the hierarchy are defined and change slowly over time, short term planning can adapt to local changes in the environment. Also, ideally blocks of abstraction could be learned independently and changed interchangeably depending on the situation.
Why active inference?
Using active inference to navigate remove any need for task training, our model would learn to imagine the structure of the environment and the active inference will use the predictions of the agent over the environment to plan the optimal path to objective or to explore.
The agent then navigate purely driven by active inference scheme.
Trying to get the minimise Expected Free Energy (EFE) \(G(\pi)\) while choosing a policy \(\pi\). The EFE of each policy at timestep T is calculated such that:
\[\begin{equation} G(\pi,T) = \underbrace{D_{KL}[Q(z_T|\pi)||P(z_T)]}_\text{Exploration} \space \underbrace{ - \mathbb{E}_{Q'(\tilde{o}|\pi)}[lnP(\tilde{o}|C)]}_\text{Preference\_seeking} \end{equation}\]The exploration is based on the premise that we want to move toward an expected state (here \(z\)) that allows us to learn the most (info gained by moving, read more about exploration in the blog post Latent Bayesian Surprise up to Bayesian surprise), while the exploitation, or preferrence seeking part favorise policies leading toward expected observations \(\tilde{o}\) (with \(\tilde{o}\) being the sequence of observations expected given a sequence of action -or policy \(\pi\)-) ressembling the preferred observation \(C\)
The probability of a policy being chosen is then:
\[\begin{equation} P(\pi) = \sigma (-\gamma G(\pi)) \end{equation}\]With \(\sigma\) being a softmax over the EFE of the policies and \(\gamma\) a temperature added to regulate how contrasted will the probabilities be between the one having the highest and lowest probability.
In practice exploration or exploitation are weighted depending on the situation. Thus we can balance out which behaviour we want to favor.
If there are no preferred observations to give the model then the agent explore, else it will do it’s utmost to reach the preferred state instead
The observation is not a full real observation but can be any type of partial observation such as a color or a shape. Thus the preferred observation comes from memory and imagination instead of a given ground truth observation. Allowing the agent to be independent of the environment.
The Hierarchy
In this model we use different models at each level of hierarchy to palliate the shortcoming of each of them. In bold are limitations palliated by the model hierarchy
Cognitive map
The high level produces a topological map, it learns the overall world structure and the connection between places. The layout is relatively similar to what is described in the blog post LatentSLAM.
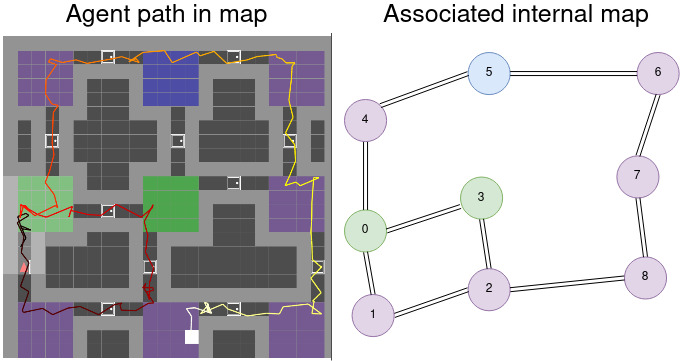
Whenever the agent moves to a new location it creates a new node for it and link it to the previous location. As can be seen above, upon recognising the place, close loop is realised.
PRO
- It stores information in a compact representation easy to represent for humans.
- It is rather robust to changes in he environment as the layout is high level
- It allows for efficient long term planning over long distances
- It can allow for semantic understanding of the environment by capturing meaningful spatial relationship between places.
Limitation
-
Highly complex environments composed of intricated geometry or fine grained details is a challenge of representation for the topological map
-
Also it assume the overall connectivity of the places are not going to change and no place is going to disappear
-
However this kind of place have relative location between each other but isn’t exact. That is not an issue in itself as navigation is adapted in the lower layers and the high level map is used for general goal setting, giving a direction to reach.
-
Another possible limitation is the engineering those kind of map requires, it assumes some constraints and conditions to define what a location is and allow close-looping.
Allocentric model
At the second layer of the hierarchy we have the allocentric map, based on the blog post Active vision. This model is tasked with learning the structure of the world as chunk of information.
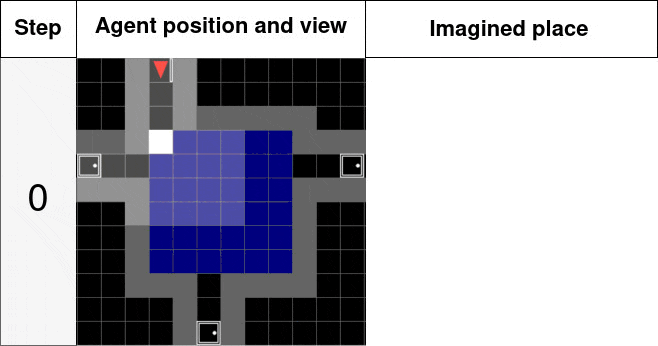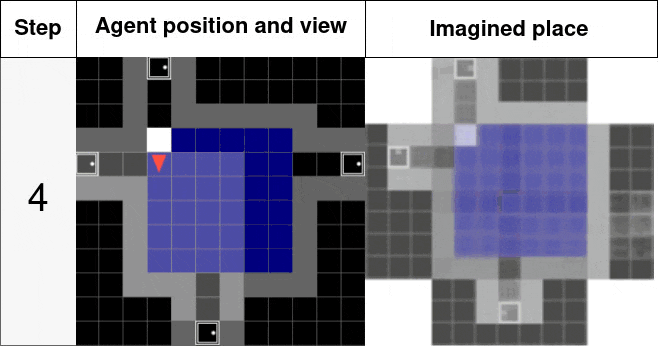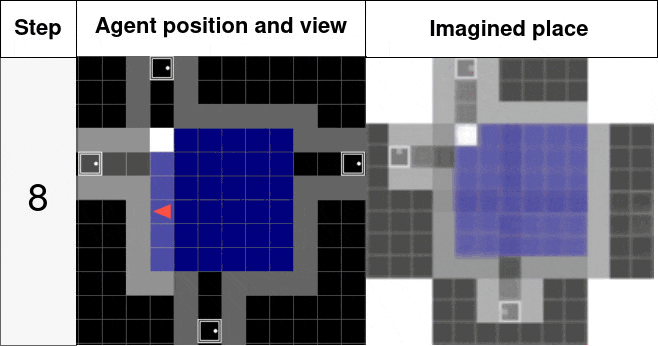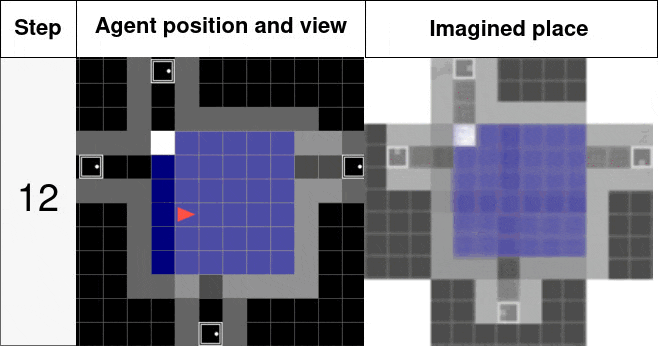
Below you can see its structure with the place z being updated with each new pose p and observation o then being able to predict any new observation from unvisited pose p. The right gif shows this mechanism in action, a place is generated over consecutive observations and gets more and more accurate. Then from any pose in this room, the observation is expected to be accurate as well.
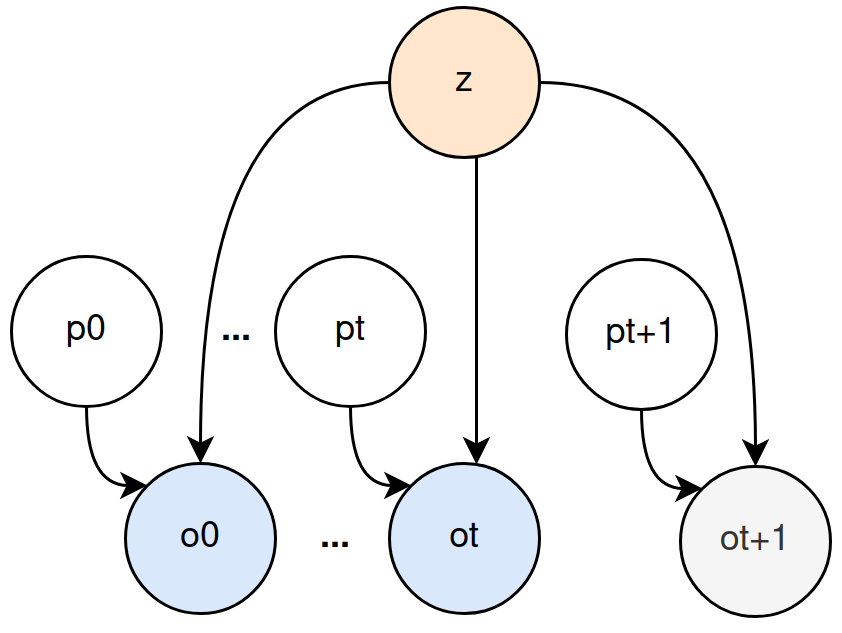 |
| 
PRO
- It forms a rich representation of a scene allowing it to learn structures and relationship of the environment in a 3D setting can generate the viewed scene even from novel viewpoints and angles
- It can handle partial or incomplete observations, inferring what is missing to represent the scene.
- It can imagine the agent at any position in any place simultaneously
Limitation
-
Once it becomes confident about a place layout it will hardly change it given new evidence, so new obstacles might not be accounted for. Making it a static memory of the place
-
Training over limited data can easily lead to overfiting
-
The efficiency of the structure is heavily dependent on the quality of the training and chosen hyper-parameters
-
Complex scene were objects hide each others from view might prove difficult for the model to infer correctly the complete place.
Egocentric model
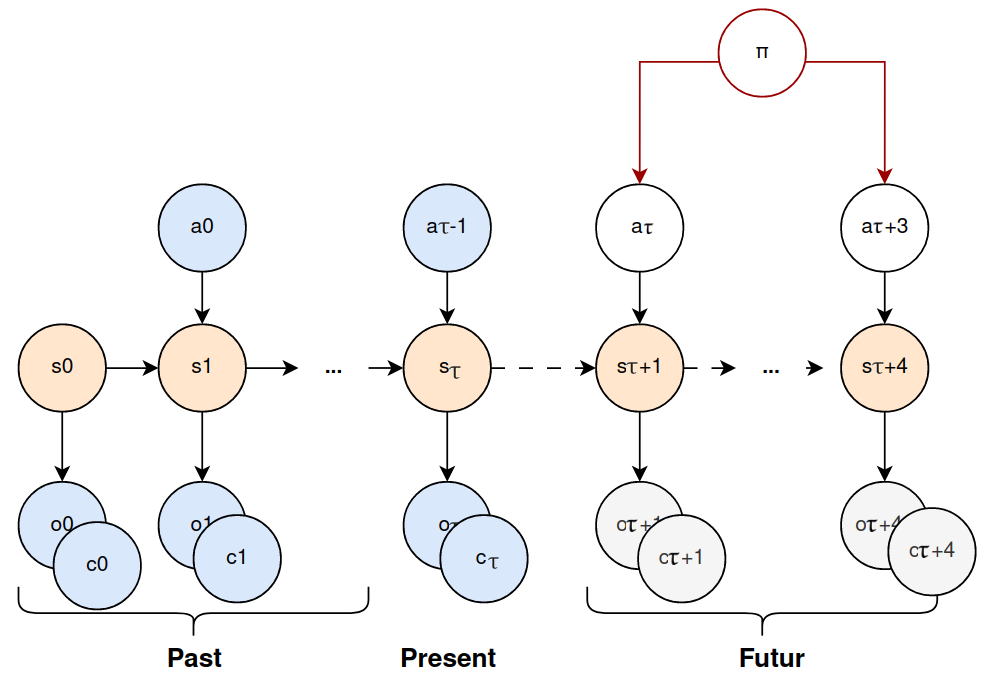
The lowest level of the hierarchy us there to infer the dynamic of the agent and locally correct the allocentric model memory to the reality of the environment if need be. The internal process is similar to the blog post Robot imaginations with the following POMDP schematics. s being the state of the egocentric model, a the action and o,c the visual observation and collision imagined by the state.
Pro
- Learn a generative model purely from data without specifying any transition dynamics or meaning to the state spaces upfront.
- Capture the dynamics and the ambiguity of the environment well enough to be able successfully
- Represent the environment in a its own belief states.
Limitation
- can not keep a mental “map” of the environment
- it has a short term memory
- it has a limited lookahead, the further goes the prediction, the less accuarte is the prediction
Conclusion
We offer an insight on the capacity of spatial and temporal hierarchy coupled with active inference and shows promise for enhanced navigation in familiar environments.
However it is still slow in computation and is not yet adapted for unfamiliar environment structure learning.