When we need to take a decision in life, we typically iterate over our available options, and consider all their pros and cons. For each option, we imagine the possible consequences by mentally rolling out “what-if” scenarios, and evaluate how good the different outcomes match our preferences. Can we have robots operate the same way, by equipping them with a camera sensor?
Learning by minimizing surprise
First, the robot needs to be able to generate these imaginations, i.e. assessing what will happen if I do this or that. To accomplish this, equip the robot with a generative world model, which is trained from data by minimizing its surprise. Put shortly, the robot learns to understand its environment, by constantly trying to predict the future. The better its understanding, the lower the prediction errors, which renders the environment less surprising.
More formally, the generative model of the robot consists of a prior model \(p_\xi\), predicting the next state from the current state and action; a posterior model \(q_\phi\), predicting the next state given current state and action, and a sensory observation; and a likelihood model \(p_\theta\), predicting the sensory observation from the state.
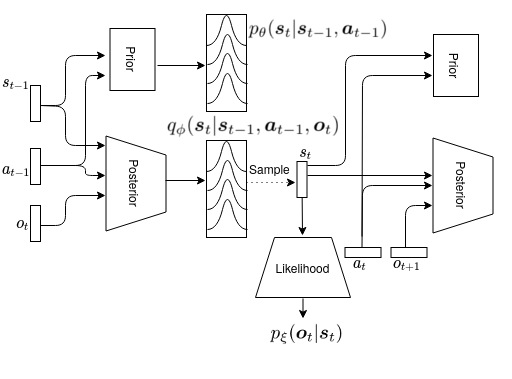
Minimizing surprise then boils down to optimizing parameters \(\xi\),\(\phi\) and \(\theta\):
\[\begin{equation} \label{eq:model-obj} \forall t : \underset{\phi, \theta, \xi}{\text{minimise}}: -\log p_\xi(\mathbf{o}_t \vert \mathbf{s}_t) + D_{\mathrm{KL}} (q_\phi(\mathbf{s}_t \vert \mathbf{s}_{t-1}, \mathbf{a}_{t-1}, \mathbf{o}_{t}) \Vert p_\theta(\mathbf{s}_{t} \vert \mathbf{s}_{t-1}, \mathbf{a}_{t-1})) \end{equation}\]Robot imaginations
We implemented this on a real robot, by first gathering data teleoperating the robot through our lab, while recording the action commands and a first person camera view.
After training, our robot is actually able to generate “what-if” scenarios, by estimating possible futures with the prior model, and visualizing possible sensory observations using the likelihood model.
As our model is action-conditioned, the robot can imagine what will happen when turning left, going straight ahead or turning right.
Why is this useful?
Having robots that can learn the effect of their actions on their environment is an important step towards intelligent, autonomous systems. For example, the generative model as presented here can be used to create robust controllers for vision-based robot navigation1. This model can also be used to detect dangerous anomaly situations, by evaluating the robot’s surprise following recent sensory observations. When new observations don’t match the robots predictions, it might be useful to trigger an alarm 2.
We believe generative world models are indispensible for developing artificial intelligent systems. For example, a big drawback of using current deep learning algorithms in autonomous decision systems is not being able to assess why a certain decision was taken, due to their black box nature. A generative model like ours allows to litterally query the robot “what were you thinking?”, which might give better insight in the robot’s decision process. Apart from that, these models might be a first step towards artificial embodiment and consciousness.
-
Ozan Çatal, Samuel Wauthier, Tim Verbelen, Cedric De Boom, Bart Dhoedt, Deep Active Inference for Autonomous Robot Navigation, BAICS workshop at ICLR, 2020. ↩
-
Ozan Çatal, Sam Leroux, Cedric De Boom, Tim Verbelen and Bart Dhoedt, Anomaly Detection for Autonomous Guided Vehicles using Bayesian Surprise, IROS, 2020. ↩