Moving from place to place comes without thinking for humans, yet it is something robots continue to struggle with for decades. While there have been tremendous advances in the field of SLAM (simultaneous localisation and mapping, the field that concerns itself with robotic navigation) current approaches still fail to produce stable maps that can be utilised for a long time. We propose a first step towards combining biologically plausible SLAM systems (i.e. RatSLAM) with deep learning systems such as our neuroscience-inspired dynamics model. RatSLAM distinguishes itself from other more traditional SLAM algorithms in three ways.
- It is fully based on a model of how a rat represents the space and its location therein.
- It builds a topological map instead of a metric map.
- It allows for life-long mapping “out of the box”
RatSLAM, Rats and hippocampi
Let me preface this section with a disclaimer that we are by no means experts on the physiology of brains and rats, so the following discussion will focus on the higher level picture.
The rat brain has been studied for a long time in order to get to better understanding of how human cognition might work. An interesting aspect that arose from studying rat brains is the discovery of place and grid cells in the hippocampus. These cells work together to form a cognitive map, firing when the animal moves through specific locations in the terrain and spatially periodic array of locations. Finally, the discovery of head direction cells formed a basis for our understanding on how localisation and mapping might occur in the biological brain. In short, it appears that the brain has specialised cells optimised for localisation and navigation. A detailed description of these cells and processes can be found here
It is this notion that RatSLAM aims to mimic in order to transfer the navigational behaviour of animals to robots. It achieves this by integrating grid and head-direction cells into so-called pose cells which encode the robots position in x-y- space. These pose cells are arranged in a continuous attractor network (CAN), wrapping around each edge. A CAN be most easily visualised as a cube in 3D that wraps around in space. Similar to the environment of Pac-Man where the player always teleports back to the opposite edge when reaching the end of the map. In this pose CAN estimates of the robots position are encoded through activity packets. Activity in a CAN carries a similar meaning as in the actual brain, it corresponds to some excitatory pattern. The current estimate of the robot pose is the one associated with the activity packet with the highest activation. The CAN pose estimates are updated by the robotic internal odometry, in a process similar to dead-reckoning. Of course robust navigation also needs some form of path calibration mechanism, augmented by sensory cues. RatSLAM facilitates this by utilising view-cells. These cells are arranged in an array and contain templates of distinct sensory cues and the pose cell readout of the moment the cue was experienced. Once a cue is re-encountered the closest matching view-cell template will inject activity in the CAN at the location stored in the view-cell. This will influence the current location estimate of the robot based on how strong the connection between the view-cell position and the cue is. Finally, the robot should be able to track it’s location beyond the finite scope of the CAN. In order to achieve this RatSLAM keeps track of past experiences by combining pose cell activity packets and view-cells to create experiences and linking them together in a graph like structure. This ability to store data in an ever-growing graph allows for a form of life-long mapping, as Michael Milford has shown in earlier work 1. The complete system can be sketched schematically as shown below.
Active inference for view-cells and planning
In an earlier blog and paper we’ve discussed how a learned dynamics model using the active inference objective is capable of learning how to steer a robot towards a known goal observation while being relatively unaffected by observational aliasing i.e., similar but distinct observations that are mapped to the same view-celsl templates, in the world. The problem with this model is that the robot is unaware of the layout of the world outside it’s own short-term predictive capabilities. Combining active inference dynamics with RatSLAM therefore seems a match made in heaven. By replacing view-cell templates with latent state samples of the observational cue, we make the view-cells more robust against observational aliasing. Through the pose-cell CAN and experience map we allow for the explicit exposure of spatial information. The advantages of exposing both the pose CAN information as well as the experience graph are twofold. We now have a mechanism to plan long-term throughout the environment by setting the latent states stored in the experience graph as preferred states for the dynamics model. On top of that we can get long term coherent imaginations again through the interaction between the dynamics model and the experience map. We’ll discuss this more formally in a future post.
In practice
We tested our latentSLAM model on pre-recorded sequences captured in our lab.
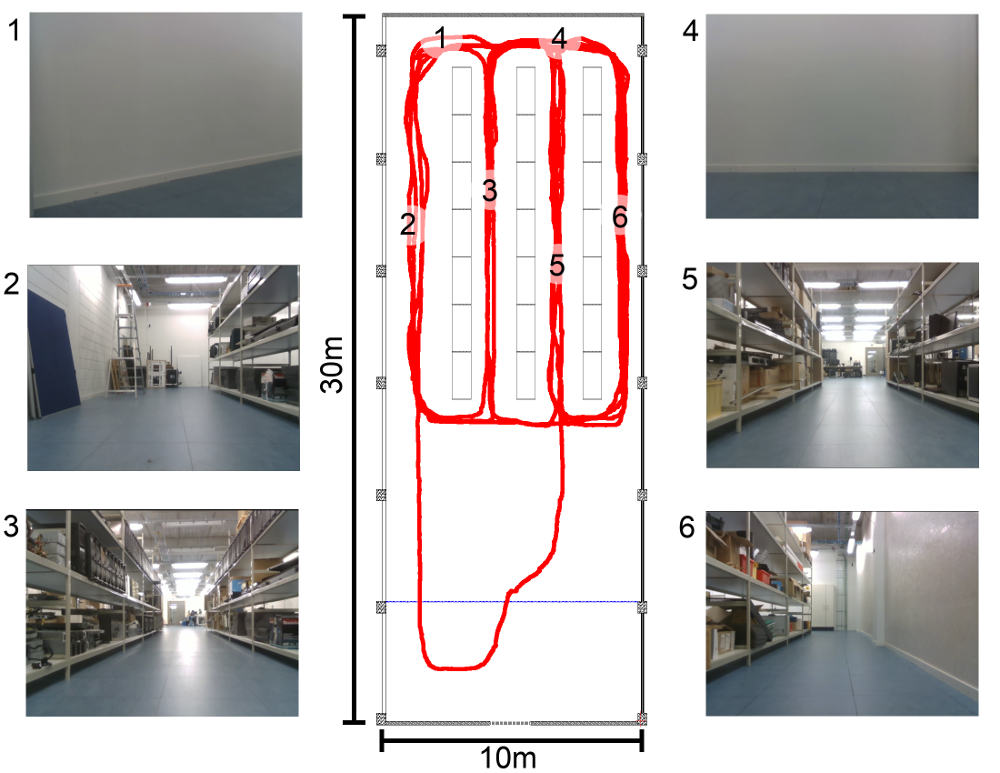
As can be seen in the video’s below our LatentSLAM model creates a map that resembles the ground-truth map very closely even though the mapping is purely topological. The usage of latent space samples greatly reduces the memory footprint of the map, making it better suited for long running experiments.
Why does this matter
Robust localisation and navigation is a necessary requirement for true robotic autonomy. The results presented in our paper show that LatentSLAM offers an interesting approach to SLAM off the beaten track, whilst drawing inspiration from nature. Combining active inference latents reduces visual aliasing while still keeping a small map size due to the low dimensionality of the latent space. Furthermore, the ability to imagine future outcomes and visualise them offers an interpretable model for navigation.