People are capable of recognizing and interacting with a plethora of different objects entering in their daily lives. However, object detection and manipulation still proves difficult for current robotic systems. Deep learning methods achieve astonishing performance on detecting known objects, for example using the YOLO object detection algorithm, however these techniques fail when unknown objects enter the scene, or the objects are placed in cluttered environments.
To tackle this fundamental problem, we inspire ourselves on the Thousand Brains Theory of Intelligence 1, recently proposed by Jeff Hawkins. This theory posits that the neocortex is composed of many elementary building blocks, called cortical columns, which build a model for objects (or more generally, concepts) in a local reference frame. As a first step towards an artificial model that implements this principle, we propose “Cortical Column Networks” (CCN). A CCN is a particular neural network, focused on identifying and representing an object in an internal reference frame. A collection of CCNs can then be used to identify an observed object using a voting mechanism.
The Thousand Brains Theory
The Thousand Brains Theory is a theory explaining the inner workings of the neocortex. The base premise is that the neocortex is built from basic components, called cortical columns, that all process information in the same way, building a model of the world. In essence, every cortical column is a sensory-motor system, which processes part of your sensory input, makes inferences about the object at hand, and predicts how the sensory information will change upon action. To make such predictions, it needs to learn an object reference frame, in order to infer what part of the object you are sensing.
Jeff Hawkins often gives the example of your finger touching a coffee cup. With only one touch you probably don’t know it’s a cup, but by moving your finger over the surface of the cup, you can feel the edges and the handle, therefor inferring it’s a cup. However, if you immediately get input from multiple fingers you’ll probably be faster at inferring the object identity. This can be seen as multiple cortical columns inferring the object category, by means of ``voting’’ for their current inferences.
Of course there is much more to it, which is beautifully described in Jeff Hawkins’ book “A Thousand Brains”, which is highly recommended 1.
How do these CCNs work?
Inspired by Thousand Brains Theory, we adopt he following take-aways. First, our brain is built from basic building blocks that act according to the same algorithm. Second, each building block is a sensory-motor system, that predicts novel sensory inputs after moving, by learning representations w.r.t. an object’s local reference frame. Third, our ultimate conscious experience of what the object is, is formed after combining “votes” of the different blocks.
In our case, we propose a Cortical Column Network (CCN) as a basic building block, which learns object representations from camera input (i.e. pixels). Crucially, we can move our camera around, querying novel viewpoints of the object at hand. For each novel object category, we create a novel CCN, which is trained to predict both the object identity and a pose in an object-centric reference frame, by predicting novel views after moving the camera. This is consistent with the two-stream hypothesis of visual information processing in the brain using a dorsal and a ventral stream that distinctly represent the object pose and identity 2. Hence, the model CCN is optimized according to the Free Energy Principle 3, in which the CCN infers a posterior belief over object identity and pose, and is trained to minimize surprise. It is important to note that the object pose is encoded in an abstract, learnt latent space, making it a true, object-centric reference frame.
For more details on the CCN architecture and training method, we refer the interested reader to the paper.
You mentioned something about voting?
According to the Thousand Brains Theory, multiple cortical columns vote on the object identity, resulting in a single, conscious experience. Similarly, when our agent looks at a new scene or object, each of its CCNs will vote whether the observed object belongs to a certain category. However, a single view might be ambiguous, and multiple CCNs might “fire”. Therefore, we aggregate the votes over time using a Dirichlet distribution, resulting in a single winner. Moreover, similar to our previous work, we can again use the predictive mechanism of the CCNs to minimize expected Free Energy and actually infer the moves that will reduce ambiguity.
In case none of the CCNs activate for a certain object category, this means this is probably a novel object, and a new CCN can be instantiated and trained, effectively having an extensible, unsupervised system that can learn about objects in the world.
How can this representation be useful for control?
In our experiments, we trained CCNs for different objects from the YCB dataset 4 in a simulated environment. For each object, a prerecorded dataset is created in which the object is observed from different camera poses. The separate CCNs are then trained on their corresponding dataset. After training, CCNs can imagine how objects would look like from different viewpoints, by traversing the latent space representing the object pose. (top: initial view, bottom: imagined trajectory):
Besides inferring the object pose, a CCN can also be used to infer the actions that bring the camera towards a certain preferred viewpoint. This can for example be used to move a robot manipulator towards an object in a certain graspable pose (top: initial observation, middle: target pose, bottom: estimated trajectory):
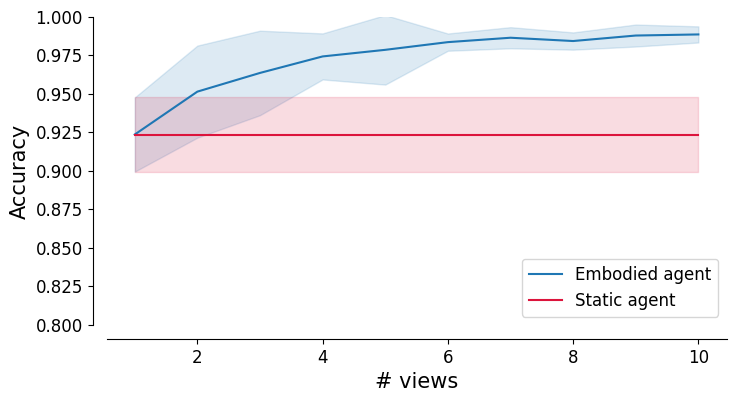
Finally, the voting mechanism allows us to accurately classify random object views into their different categories. Moreover, if we allow our agent to move around and take multiple observations, the classification further improves.
Where do we go from here?
This work is just a first step towards an artificial model that can apply continual learning to a robotic workspace. We will extend this by applying these models to real-world scenarios using a robotic manipulator in a pick-and-place scenario. We believe that learning objects in their own reference frames is key, as this provides a general framework to learn representations independent of their environments.
Moreover, this draws many parallels with navigation, where also sensory inputs are linked to a spatial reference frame, as we discussed in a previous post. This strengthens our belief that predictive models are key for any form of (artificial) intelligence.
Finally, while heavily inspired by findings from the Thousand Brains Theory, our CCNs are still very different from cortical columns in the neocortex. For instance, our CCN takes as input the complete sensory camera image, and specialize learning for a single object category, whereas each cortical column in the neocortex only processes part of the sensory inputs (i.e. some retina cell inputs) and learn more complex world models. Also many other interesting characteristics of the brain, such as hierarchical concepts and sparsity are currently lacking in our model, which offers many interesting directions for further research.
-
Jeff Hawkins. A Thousand Brains: A New Theory of Intelligence. ↩ ↩2
-
George Ettlinger. “Object vision” and “spatial vision”: The neuropsychological evidence for the distinction. Cortex, 1990. ↩
-
Karl Friston, Thomas FitzGerald, Francesco Rigoli, Philipp Schwartenbeck, John O’Doherty, and Giovanni Pezzulo. Active inference and learning. Neuroscience & Biobehavioral Reviews, 2016. ↩
-
Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M. Dollar. The YCB object and model set: Towards common benchmarks for manipulation research. In 2015 International Conference on Advanced Robotics (ICAR), 2015. ↩